W dzisiejszym świecie jesteśmy dosłownie bombardowani informacjami – za pośrednictwem mediów, zwłaszcza Internetu, dysponujemy dostępem do właściwie nieograniczonej wiedzy. Co więcej, informacje starzeją się w bardzo szybkim tempie, dlatego trudno jest śledzić choćby najważniejsze aktualności. Artykuł „Meme tracking and the Dynamics of the News Cycle” autorstwa J.Leskoveca, L. Backstroma i J. Kleinberga przedstawia cykl życia informacji i dynamikę ich propagacji w sieci na przykładzie memów.
Zgodnie z podaną definicją, pojęcie news cycle określa rytmy w mediach informacyjnych, obserwowane na przestrzeni pewnego okresu czasu. Pierwsze istotne skrócenie news cycle, który wcześniej był związany z codziennym wydawaniem gazet, zostało spowodowane przez pojawienie się wiadomości w telewizji, emitowanych kilka razy w ciągu doby – ten rodzaj cyklu jest określany mianem 24-hour news cycle i funkcjonuje do dzisiaj, aczkolwiek dostęp do informacji w Internecie zapoczątkował kolejną fazę skracania cyklu wiadomości – obecnie mówi się nawet o 5-minute news cycle, typowym dla sieci Web. Istotnie, w bardzo krótkim czasie (nawet rzędu minut) po pojawieniu się informacji w wiodących mediach można zaobserwować, jaką reakcję wywołuje ona w blogosferze oraz w sieciach społecznościowych.
Bardzo ciekawym zagadnieniem z punktu analizy dynamiki news cycle jest śledzenie memów, również szeroko opisane we wspomnianym artykule. Pod pojęciem mema rozumieć należy jednostkę informacji kulturowej zapisanej w mózgu (lub na innym nośniku), przenoszącą idee, zachowania itp., która może zostać rozpropagowana z jednego mózgu do innego poprzez informację pisaną, mówioną, gest, dźwięk czy obraz. Niektórzy badacze porównują memy do genów, zwracając uwagę na ich powielanie poprzez naśladownictwo, a także ewolucję (mutację), której podlegają memy np. podczas propagacji w sieci.
Wcześniejsze badania dynamiki news cycle miały jedynie charakter jakościowy, tymczasem autorzy przytoczonego artykułu podejmują się próby analizy ilościowej. Co więcej, dotychczasowe prace rozwijały się w dwóch głównych nurtach, różniących się poziomem granularności informacji. Pierwszy z nich, wykorzystujący podejście probabilistyczne, dobrze nadaje się do obserwacji długofalowych trendów w tematach ogólnych, przy długim horyzoncie czasowym, natomiast drugi, oparty o identyfikację linków i ekstrakcję rzadkich, nazwanych jednostek znalazł zastosowanie w śledzeniu krótkich kaskad informacji tekstowych w blogosferze. Okazuje się jednak, że ludzie odbierają informacje na poziomie krótkich fragmentów tekstu, zdań i memów, odzwierciedlających aktualne wydarzenia i istotne tematy, a rozprzestrzeniających się w sieci w stosunkowo krótkim okresie czasu (rzędu dni). Celem pracy powinno być zatem zaprojektowanie algorytmów pozwalających badać dynamikę news cycle oraz proces rozprzestrzeniania się informacji właśnie na tym pośrednim poziomie.
Metoda zaproponowana przez twórców wspomnianego artykułu polega na skalowalnej identyfikacji krótkich, rozróżnialnych zwrotów, pozostających w formie względnie niezmienionej podczas propagacji przez sieć Web, aczkolwiek podlegających pewnym mutacjom w czasie. Zaprojektowane algorytmy powinny zwracać klastry zwrotów (wraz z ich mutacjami) odpowiadających poszczególnym memom. Reprezentacja mutacji zwrotów ma postać grafu zwrotów (ang. phrase graph), będącego grafem skierowanym, w którym wierzchołki odpowiadają zwrotom, a ważone łuki – połączeniom między nimi, przy czym łuki są zorientowane od krótszego do dłuższego zwrotu. Ponadto definiuje się takie parametry, jak dolną granicę długości zwrotu (aby uniknąć analizy pojedynczych słów) i dolną granicę częstości występowania. Co więcej, usuwa się zdania, dla których zadana część wystąpień dotyczy jednej domeny, a które często stanowią spam.
Rozpoznawanie klastrów na podstawie struktury danego grafu okazuje się być trudne, jednak możliwe jest poszukiwanie zwrotów na tyle blisko powiązanych, aby mogły zostać zaliczone do zbioru odpowiadającego jednemu wyrażeniu. Autorzy artykułu postulują, iż otrzymane klastry powinny mieć postać podgrafów oryginalnego DAG, w których wszystkie ścieżki spotykają się w jednym korzeniu (ang. single-rooted graph). Możliwe jest usunięcie krawędzi o niewielkich wagach, tak, aby zdekomponować oryginalny graf na rozłączne części, rozpoczynające się od pojedynczego korzenia, powstaje jednak wówczas problem partycjonowania acyklicznego grafu skierowanego, który należy do grupy NP-trudnych. Uwzględniając ten fakt, można stworzyć klasę heurystyk, pozwalających uzyskiwać dobre rezultaty klasteryzacji w krótszym czasie. Przyjmując kilka założeń dotyczących optymalnych rozwiązań problemu podziału grafu acyklicznego skierowanego wystarczy znaleźć jedną krawędź wychodzącą z każdego węzła, należącego do rozwiązania optymalnego, by w pełni zidentyfikować optymalne komponenty. Heurystyka, zachowująca krawędź do najkrótszego zwrotu, pozwalała poprawić rezultaty o 9% w stosunku do rozwiązania bazowego (pozostawianie losowych krawędzi), zaś heurystyka zachowująca krawędź do najczęściej występującego zwrotu – aż o 12%.
Po wyznaczeniu klastrów można przejść do analizy news cycle na poziomie globalnym – przede wszystkim śledzenia dynamiki wątków w czasie oraz ich wzajemnych interakcji. Wątek (ang.thread) związany z danym klastrem rozumieć należy tu jako zbiór wszystkich elementów bazy danych zawierających jakiś zwrot należący do danego klastra. Badania dynamiki news cycle przeprowadzono na zbiorze 90 milionów dokumentów (postów na blogach oraz artykułów prasowych) pochodzących z 1.65 miliona różnych stron, odpowiadających aktywności mediów w czasie trzech miesięcy kampanii wyborczej 2008 w USA. Po odfiltrowaniu zbyt krótkich zwrotów, zbyt rzadko cytowanych i przypominających spam w bazie z początkowych 112 milionów zwrotów pozostało 47 milionów, z czego 22 miliony rozróżnialnych. Proces klasteryzacji zajął 9 godzin i zwrócił graf acykliczny skierowany o 35800 nietrywialnych komponentach, zawierających 94700 zwrotów.
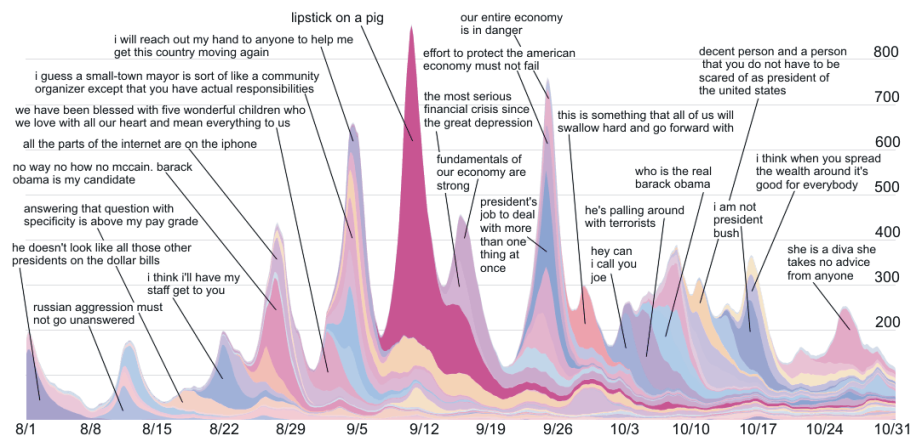
Rys 1. 50 najpopularniejszych wątków w news cycle w okresie od 1.08 do 31.10.2008.
Rys. 1 przedstawia najpopularniejsze wątki i zmiany ich istotności w czasie. Wyraźnie widoczne są trendy „rise and fall” dla poszczególnych wątków – szybko rosnąca popularność, a następnie spadek zainteresowania wątkiem. Liczba artykułów i postów była w przybliżeniu stała we wszystkie dni tygodnia, podobnie jak liczba obserwowanych zwrotów, dlatego przedstawione zmiany w czasie nie zależą od ogólnej liczby wiadomości i postów. Widoczne na zamieszczonym wykresie „spikes” wskazują okresy, gdy niewiele tematów przejmuje większość zainteresowania czytelników, natomiast okresy, w których nie ma zauważalnych „spikes” to takie, w których uwaga odbiorców nie koncentruje się na kilku kluczowych wiadomościach ale jest bardziej rozproszona.
Zaproponowane nowe podejście do globalnej analizy news cycle okazało się lepsze w porównaniu z opisanymi wcześniej metodami – opartą o model probabilistyczny i drugą, polegającą na analizie hiperlinków. Pośredni poziom granularności, zarówno w ujęciu czasowym jak i tekstowym pozwolił lepiej opisywać dynamikę news cycle. W celu zbadania jej zmian stworzono model uwzględniający takie cechy news cycle, jak naśladownictwo (ang. imitation) i czas od pierwszego pojawienia się informacji (ang. recency). Autorzy postulują, że do prawidłowego odtworzenia dynamiki news cycle konieczne są oba wspomniane czynniki – różne źródła naśladują się wzajemnie, a ponadto nowe wątki są preferowane nad starsze. Wyniki badań pokazują, że zaproponowany model pozwala uzyskać przebieg podobny do rzeczywistej dynamiki news cycle. Co więcej, uwzględnienie tylko jednego ze wspomnianych czynników uniemożliwia otrzymanie podobnego rezultatu. Jeśli wziąć pod uwagę jedynie recency, żaden z wątków nie osiąga znacząco większego zainteresowania, niż pozostałe. Z kolei uwzględnienie tylko naśladownictwa, jeden wątek uzyskuje większość zainteresowania i utrzymuje je przez cały czas symulacji – żaden inny wątek nie potrafi go zdominować, gdyż pomija się aspekt starzenia się informacji.
Dokonano także analizy lokalnej, polegającej na badaniu intensywności szczytowej popularności oraz interakcji pomiędzy artykułami a postami na blogach. Przede wszystkim sprowadzono, w jaki sposób zmienia się objętość pojedynczego wątku w czasie, przy czym objętość w chwili t jest rozumiana jako liczba jego elementów ze znacznikiem czasowym t. Czas szczytowy (ang. peak time) danego wątku, związany z jego maksymalną popularnością jest z kolei medianą wartości czasu, w których wątek pojawił się w zbiorze danych. Można by się spodziewać, że początkowa objętość danego wątku powinna być niewielka, zwiększać się przy jego cytowaniach w mediach i stopniowo zmniejszać po przeniknięciu do blogosfery. Okazuje się jednak, że wzrost i spadek objętości jest skupiony wokół wartości szczytowej i niespodziewanie symetryczny, co sugeruje szybki wzrost popularności i tak samo szybki spadek. Co więcej, blisko czasu szczytowego zmienność objętości można przybliżyć funkcją logarytmiczną postaci a|log(|x|)|, wzrastającą szybciej, niż funkcja wykładnicza (pozwalająca dobrze zamodelować przebieg zmian objętości wątku poza bliskim sąsiedztwem czasu szczytowego).
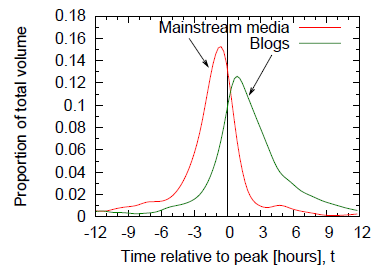
Rys 2. Opóźnienie mediów informacyjnych i blogosfery
Zazwyczaj zakłada się, że zwroty najpierw pojawiają się w mediach informacyjnych, a następnie przenikają do blogosfery. Warto jednak zastanowić się nad tym, w jaki sposób przebiega ten proces, jakie występują w nim opóźnienia czasowe oraz czy istnieje ruch danych w odwrotnym kierunku. Dokonano porównania zmian objętości dla każdego z analizowanych wątków, przy czym jedna z krzywych odpowiadała objętości dla mediów informacyjnych (news volume), zaś druga – dla blogosfery (blog volume). Rys. 2 przedstawia uzyskane przebiegi – wyraźnie widać, że czas szczytowy dla news volume występuje około 2.5 godziny wcześniej, niż dla blog volume. Ponadto, objętość wątku w mediach informacyjnych rośnie i spada szybciej, niż w przypadku blogosfery. Można także zaobserwować, iż news volume spada w szybszym tempie, niż narasta, natomiast dla blog volume występuje sytuacja odwrotna – wątki dłużej pozostają popularne w blogosferze, podczas gdy media informacyjne szybko przechodzą do innych wiadomości.
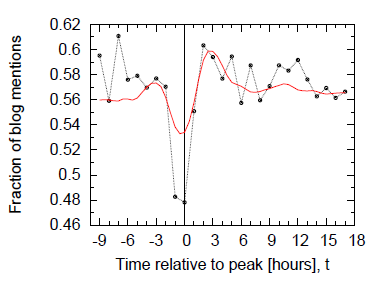
Rys 3. Migracja zwrotów z mediów informacyjnych do blogów
Zaciekawić może także fakt, iż różne strony mają różne opóźnienia we wzmiankowaniu wątków, a co więcej, popularne zwroty często najszybciej pojawiają się na blogach i w mediach niezależnych. Ponadto przeprowadzone badania wykazały, że proces przenikania zwrotów z mediów informacyjnych do blogosfery ma przebieg „rytmu serca” (ang. heartbeat), co widać na Rys. 3 – popularność zwrotu nieznacznie wzrasta około 3 godzin czasem szczytowym dla mediów informacyjnych, następnie spada, by po przekroczeniu czasu szczytowego gwałtownie wzrosnąć, co odpowiada szybkiemu przejęciu zwrotu przez blogerów. Zaskoczyć może także inne zaobserwowane zjawisko – ruch informacji, który zwykle przebiega od mediów informacyjnych do blogosfery, może zachodzić także w drugim kierunku, gdy media przejmują zwroty popularne na blogach. Mimo, że jest on stosunkowo niewielki (odpowiada ok. 3.5% całego ruchu informacji), ilustruje wzrost istotności niezależnych źródeł informacji, które wywierają zauważalny wpływ na oficjalne media.
Zagadnienie śledzenia procesu rozprzestrzeniania się informacji w sieci Web wydaje się bardzo interesujące. Wspomniany artykuł „Meme tracking and the Dynamics of the News Cycle” przedstawia całkiem nowe podejście do tego problemu, pozwalające badać dynamikę tego zjawiska w sposób ilościowy, wskazuje także podstawowe czynniki, za pomocą których można modelować news cycle. Co więcej, zwraca on uwagę na proces migracji wiadomości pomiędzy mediami informacyjnymi a blogosferą, uwydatniając wzajemne relacje między nimi.
Autor: Małgorzata Trzcielińska
Bibliografia:
J. Leskovec, L. Backstrom, J. Kleinberg „Meme tracking and the Dynamics of the News Cycle” (artykuł dostępny na stronie http://memetracker.org/)
